Data Preparing
HOW DATA IS COLLECTED
- Interviews (e.g job interviews)
- Observations (e.g scientists conduct research)
- Forms (e.g US Census Bureau)
- Questionaires
- Surveys
- Cookies (e.g websites)
DATA COLLECTION CONSIDERATIONS
- How the data will be collected
- Choose data sources
- First-party data: Data collected by individual group using their own resources
- Second-party data: Data collected by a group directly from its audience and then sold
- Third-party data: Data collected from outside sources who did not collect it directly
- Decide what data to use
- Solving your business problem: Dataset can show a lot of interesting information. But be sure to choose data that can actually help solve your problem question. For example, if you are analyzing trends over time, make sure you use time series data - in other words, data that include dates
- How much data to collect: If you are collecting your own data, make reasonable decisions about sample size. A random sample from existing data might be fine for some projects. Other projects might need more strategic data collection to focus on certain criteria. Each project has its own needs.
- Select the right data type
- Time-frame for data collection: If you are collecting your own data, decide how long you will need to collect it, especially if you are tracking trends over a long period of time. If you need an immediate answer, you might not have time to collect new data, in this case, you would need to use historical data that already exists
PRIMARY VS SECONDARY DATA
| Data format classification | Definition | Examples |
|---|---|---|
| PRIMARY DATA | Collected by a researcher from first-hand sources | - Data from an interview you conducted - Data from a survey returned from 20 participants - Data from questionnaires you got back from a group of workers |
| SECONDARY DATA | Gathered by other people or from other research | - Data you bought from a local data analytics firm's customer profiles - Demographic data collected by a university - Census data gathered by the federal government |
INTERNAL VERSUS EXTERNAL DATA
| Data format classification | Definition | Examples |
|---|---|---|
| Internal data | Data that is stored inside a company's own system | - Wages of employees across different business units tracked by HR - Sales data by store location - Product inventory levels across distribution centers |
| External data | Data that is stored outside of a company or organization | - National average wages for the various positions throughout your organization - Credit reports for customers of an auto dealership |
CONTINUOUS VS DISCRETE DATA
| Data format classification | Definition | Examples |
|---|---|---|
| Continuous data | Data that is measured and can have almost any numeric value | - Height of kids in third grade classes - Runtime markers in a video - Temperature |
| Discrete data | Data that is counted and has limited number of values | - Number of people who visit a hospital on a daily basis (100,200,1000) - Maximum capacity allowed in a room - Tickets sold in the current month |
QUALITATIVE VS QUANTITATIVE DATA
| Data format classification | Definition | Examples |
|---|---|---|
| Qualitative | A subjective and explanatory measure of a quality or characteristic | - Favorite exercise activity - Brand with best customer service - Fashion preference of young adult |
| Quantitative | A specific and objective measure, such a number, quantity, or range | - Percentage of board certified doctors who are women - Population size of elephants in Africa - Distance from Earth to Mars at a particular time |
NOMINAL VS ORDINAL DATA
| Data format classification | Definition | Examples |
|---|---|---|
| Nominal | A type of qualitative data that us categorized without a set order | - First time customer, returning customer, regular customer - New job applicant, existing applicant, internal applicant - New listing, reduced price listing, foreclosure |
| Ordinal | A type of qualitative data with a set order or scale | - Moving rating (1 star, 2 stars) - Ranked-choice voting selections (1st, 2nd) - Satisfaction level measured in a survey (satisfied, neutral, dissatisfied) |
STRUCTURED VS UNSTRUCTURED DATA
| Data format classification | Definition | Examples |
|---|---|---|
| Structured data | Data organized in a certain format, like rows ad columns | - Expense report - Tax return - Store inventory |
| Unstructured data | Data that cannot be stored as columns and rows in a relational database | - Social media posts - Emails - Videos |
- Data model: A model that is used for organizing data elements and how they relate to one another.
- Data elements: Pieces of information, such as people's names, account numbers, and addresses
SPREADSHEETS
-
3 kind of data types in spreadsheets:
- Number: Numeric can be add, subtract, etc.
- Text or string: Names, addresses, date
- Boolean: True or False
-
A data table can have very simple structure:
- Rows called Records
- Columns called Fields
-
Wide data: Is a dataset in which every data subject has a single row with multiple columns to hold the values of various attributes of the subject. It is helpful for comparing specific attributes across different subjects.
-
Long data: Is data in which each row represents one observation per subject, so each subject will be represented by multiple rows. This data format is useful for comparing changes over time or making other comparisons across multiple subjects.
TRANSFORMING DATA:
-
What is data transformations?
- Data transformation is the process of changing the data's format, structure, or values. As a data analyst, there is a good chance you will need to transform data at some point to make it easier for you to analyze it.
- Data transformation usually involves:
- Adding, copying, or replicating data
- Deleting fields or records
- Standardizing the names of variables
- Renaming, moving, or combining columns in a database
- Joining one set of data with another
- Saving a file in a different format. For example, saving a spreadsheet as a comma separated values
(.csv)
-
Why transform data?
- Goals for data transformation might be:
- Data organization: better organized data is easier to use
- Data compatibility: different applications or systems can then use the same data
- Data migration: data with matching formats can be moved from one system to another
- Data merging: data with the same organization can be merged together
- Data enhancement: data can be displayed with more detailed fields
- Data comparison: apples-to-apples comparisons of the data can then be made
- Goals for data transformation might be:
-
Data transformation example: data merging
- Mario is a plumber who owns a plumbing company. After years in the business he buys another plumbing company. Mario wants to merge the customer information from his newly acquired company with his own, but the other company uses a different database. So, Mario needs to make the data compatible. To do this, he has to transform the format of the acquired company's data. Then, he must remove duplicate rows for customers they had in common. When the data is compatible and together, Mario's plumbing company will have a complete and merged customer database.
-
Data transformation example: data organization (long to wide)
- To make it easier to create charts, you may also need to transform long data to wide data. Consider the following example of transforming stock prices (collected as long data) to wide data.
- Long data is data where each row contains a single data point for a particular item. In the long data example below, individual stock prices (data points) have been collected for APPL, AMZN, GOOGL on the given dataset.
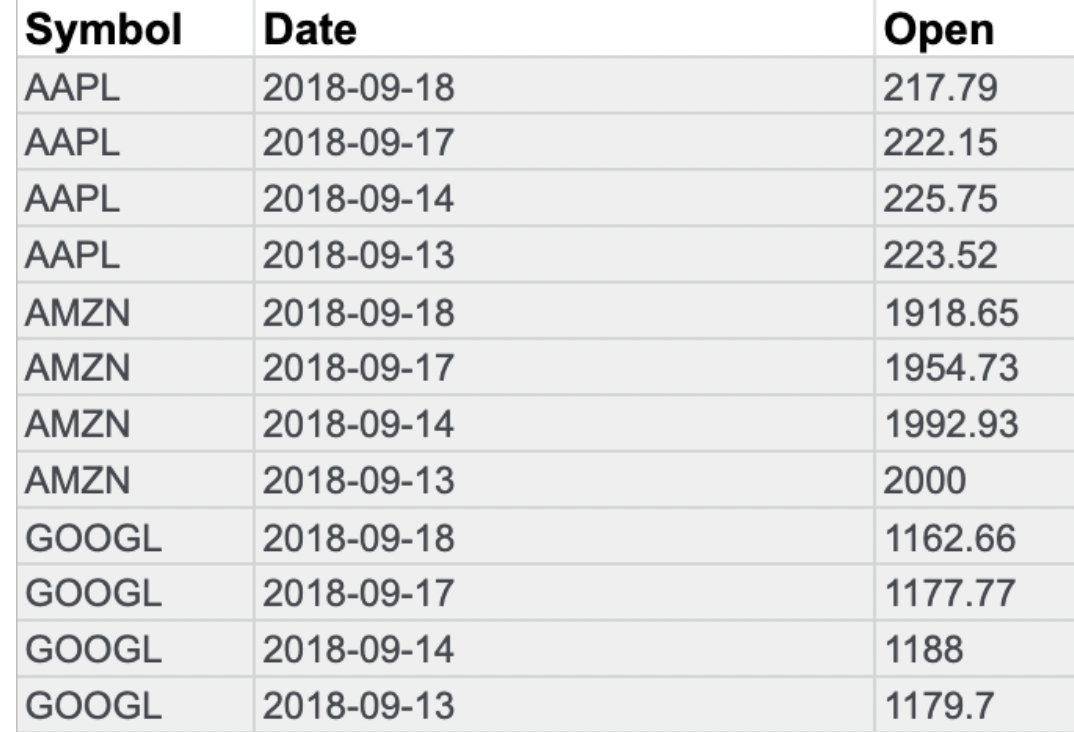
- Wide data is data where each row contains multiple data points for the particular items identified in the columns
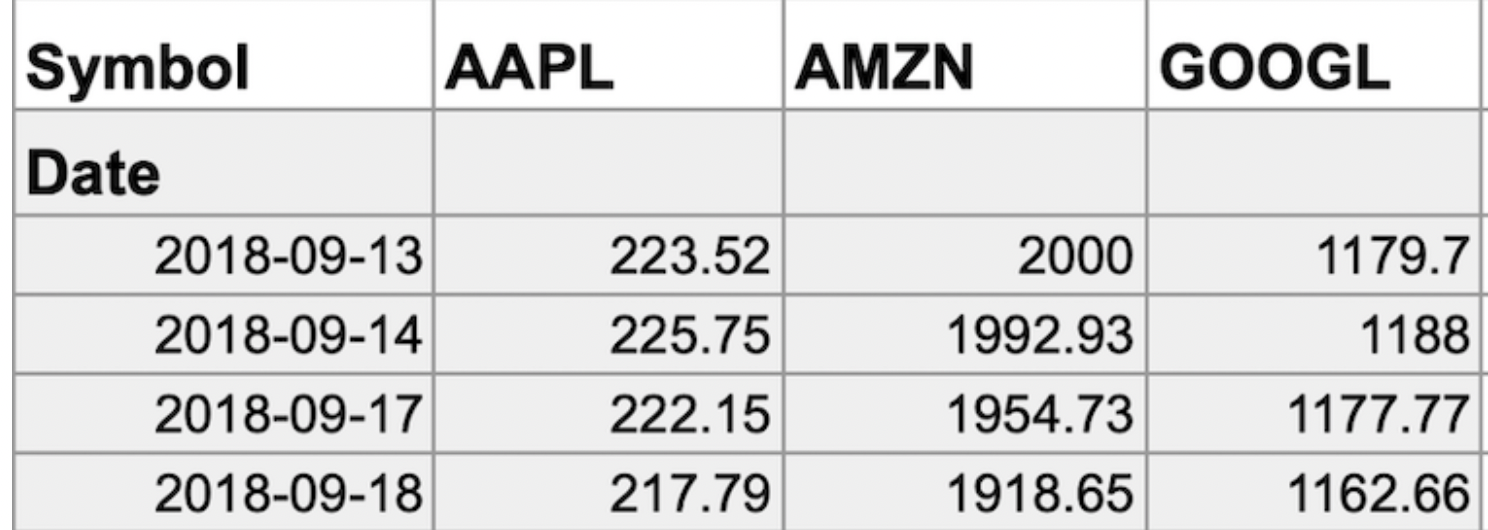
- With data transformed to wide data, you can create a chart comparing how each company's stock changed over the same period of time.
- You might notice that all the data included in the long format is also in the wide format. But wide data is easier to read and understand. That is why data analysis typically transform long data to wide data more often than they transform wide data to long data. The following table summarizes when each format is preferred:
| Wide data is preffered | Long data is preferred |
|---|---|
| Creating tables and charts with a few variables about each subject | Storing a lot of variables about each subject. For example, 60 years worth of interest rates for each bank |
| Comparing straightforward line graphs | Performing advanced statistical analysis or graphing. |
TYPES OF DATA BIAS:
- Sampling bias: A sample that is not representative of the whole population.
- Observer bias (experimenter bias / research bias): The tendency for different people to observe things differently
- Interpretation bias: The tendency to always interpret ambiguous situation in a positive or negative way
- Confirmation bias: The tendency to search for or interpret information in a way that confirms pre-existing beliefs
VALIDATION FOR GOOD DATA:
- Reliable : Who created the data set? Is it part of a credible organization
- Orginal
- Comprehensive
- Current: When the data was last refreshed?
- Cited
ETHICS
-
Ethics: Well-founded standards of right and wrong that prescribe what humans ought to do, usually in terms of rights, obligations, benefits to society, fairness, or specific virtues.
-
Data ethics: Well-founded standards of right and wrong that dictate how data is collected, shared, and used.
-
Aspects of data ethics:
- Ownership: Individuals who own the raw data they provide, and they have primary control over its usage, how it's processed, and how it's shared
- Transaction transparency: The idea that all data processing activities and algorithms should be completely explainable and understood by the individual who provides their data.
- Consent: An individual's right to know explicit details about how and why their data will be used before agreeing to provide it
- Currency: Individuals should be aware of financial transactions resulting from the use of their personal data and the scale of these transactions
- Privacy:
- Protection from unauthorized access to our private data
- Freedom from inappropriate use of our data
- The right to inspect, update, or correct our data
- Ability to give consent to use our data
- Legal right to access the data
- Data anonymization:
- Telephone numbers
- Names
- License plates
- Social security numbers
- IP addresses
- Medical record
- Email addresses
- Photographs
- Account number
- Openness: Free access, usage, and sharing of data
- Availability and access: Open data must be available as a whole, preferably by downloading over the Internet in a convenient and modifiable form (e.g: data.gov where you can download science and research data for a wide range of industries in format like spreadsheets)
- Reuse and Redistribution: Open data must be provided under terms that allow reuse and redistribution including the ability to use it with other datasets
- Universal participation: Everyone must be able to use, reuse, and redistribute the data. There shouldn't be any discrimination against fields, persons, or groups
-
Data interoperability: The ability of data systems and services to openly connect and share data
METADATA
-
Database: A collection of data stored in a computer system
-
Metadata: Data about data (data source, how it was collect, attributes, etc. help analyst understand the data context)
-
Relational database: A database that contains a series of related tables that can be connected via their relationships
-
Primary key: An identifier that references a column in which each value is unique (unique and cannot be null or blank)
- Used to ensure data in a specific column is unique
- Uniquely identifies a record in a relational database table
- Only one primary key is allowed in a table
- Cannot contain null or blank values
-
Foreign key: A field within a table that is a primary key in another table
- A column or group of columns in a relational database table that provides a link between the data in two tables
- Refers to the field in a table that's the primary key of another table
- More than one foreign key is allowed to exist in a table
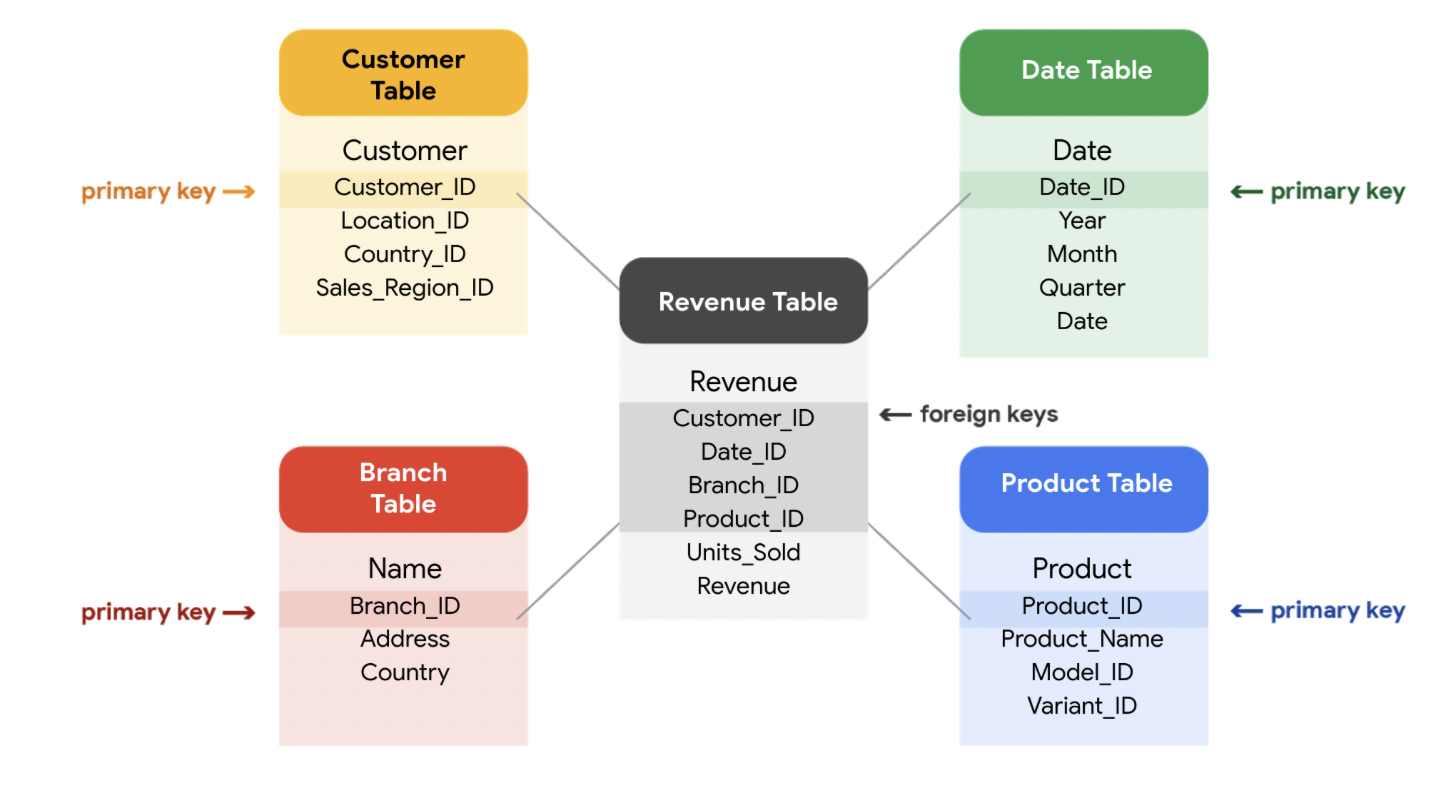
-
3 types of metadata:
- Descriptive: Metadata that describes a piece of data and can be used to identify it at a later point in time
- Structural: Metadata that indicates how a piece of data is organized and whether it is a part of one, or more than one, data collection
- Administrative: Metadata that indicates the technical source of a digital asset
-
Benefits of metadata:
- Reliability: Data analyst use reliable and high-quality data to identify the root cause of any problems that might occur during analysis and to improve their result. If the data being used to solve a problem or to make a data-driven decision is unreliable, there's a good chance the results will be unreliable as well.
- Metadata helps confirm the data:
- Is accurate
- Is precise
- Is relevant
- Is timely
- Metadata helps confirm the data:
- Consistency: Data analyst thrive on consistency and aim for uniformity in their data and databases helps make this possible. For example, to use survey data from two different sources, data analysts use metadata to make sure the same collection methods were applied in the survey so that both datasets can be compared reliably.
- When data is uniform, it is:
- Organized: Data analyst can easily find tables and files, monitor the creation and alteration of assets, and store metadata
- Classified: Data analysts can categorize data when it follows a consistent format, which is beneficial in cleaning and processing data
- Stored: Consistent and uniform data can be efficiently stored in various data repositories. This streamline storage management tasks such as managing a database
- Accessed: Users, applications, and systems can efficiently locate and use data
- When data is uniform, it is:
- Reliability: Data analyst use reliable and high-quality data to identify the root cause of any problems that might occur during analysis and to improve their result. If the data being used to solve a problem or to make a data-driven decision is unreliable, there's a good chance the results will be unreliable as well.
-
Metadata repositories:
- Metadata repositories help data analyst ensure their data is reliable and consistent
- Metadata repositories are specialized databases specifically created to store and manage metadata. They can be kept in a physical location or a virtual environment - like data that exists in the cloud
- Metadata repositories describe where the metadata came from and store that data in an accessible form with a common structure. This provides data analysts with quick and easy access to the data. If data analyst didn't use a metadata repository, they would have to select each file to look up its information and compare the data manually, which would waste a lot of time and effort.
- Data analyst also use metadata repositories to bring together multiple sources for data analysis. Metadata repositories do this by describing the state and location of the data, the structure of the tables inside the data, and who accessed the user logs
-
Metadata of external databases:
- Data analysts should understand the metadata of external databases to confirm that it is consistent and reliable. In some cases, they should also contact the owner of the third-party data to confirm that it is accessible and available for purchase. Confirming that the data is reliable and that the proper permissions to use it have been obtained are best practices when using data that comes from another organization.
-
Data governance: A process to ensure the formal management of a company's data assets
IMPORT RANGE AND IMPORT HTML:
=IMPORTRANGE("URL", "sheet_name!cell_range")to import data from another google sheet.- `=IMPORTHTML("URL", "QUERY", INDEX e.g: ### Importing HTML tables with Google Sheets
1 – Open a new spreadsheet in Google Sheets. In an empty cell enter the following formula:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_S%26P_500_companies", "table", 1)
The formula IMPORTHTML requires 3 inputs:
URL:"https://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
This is the URL of the page we will import data from. It should include the protocol (e.g. http:// or https://), and be enclosed in quotation marks. Alternatively, it can be a reference to a cell in your workbook that contains the relevant URL.
QUERY:"table"
Google Sheets also gives you the option to import lists from a webpage. Search for a list element (either an unordered list, tag <ul>, or an ordered list, tag <ol>). Each list item starts with the<li> tag.
It can be either “list” or “table”, depending on the type of the webpage’s element that you want to import data from. It should also be enclosed in quotation marks. In this example, we are importing a table.
INDEX:1
The index, starting at 1, identifies which table or list should be returned from the page’s HTML source. This is useful if your page contains multiple tables or lists.
2 – Press Enter and enjoy the imported data. This import is dynamic and will update automatically when new data is added to the table. That can be useful when scraping tables that are frequently updated, for example, results of sports competitions or elections.
3 – You can download this newly created data set as .xlsx, .csv. or .tsv for further manipulation, or connect to it directly from Tableau Desktop by selecting “Google Sheets” from the list of servers.
BEST PRACTICES WHEN ORGANIZING DATA
- Naming conventions: Consistent guidelines that describe the content, data, or version of a file in its name
- The project's name
- The file creation date
- Revision version
- Consistent style and order
- Example: SalesReport_20231112_v02
- Foldering: create folder and sub folders in a logical hierachy.
- Archiving older files
- Align your naming and storage practices with your team
DATA SECURITY:
- Data security: Protecting data from unauthorized access or corruption by adopting safety measures.
- Access control permission on spreadsheets tool.
- Encryption: Uses a unique algorithm to alter data and make it unusable by users and applications that don't know the algorithm. This algorithm is saved as a "key" which can be used to reserve the encryption; so if you have the key, you can still use the data in its original form
- Tokenization: Replaces the data elements you want to protect with randomly generated data referred to as a "token". The original data is stored in a separate location and mapped to the tokens. To access the complete original data, the user or application needs to have permission to use the tokenized data and the mapping. This means that even if the tokenized data is hacked, the original data is still safe and secure in a separate location.
- Version control: Enables all collaborators within a file to track changes over time. You can understand who made what changes to a file, when they were made, and why.